
The Master Library
(and why I've been away for so long)

Some of you may have noticed I’ve been absent/quiet for several weeks1.. apologies, and I don’t expect it to happen again anytime soon. After reading this piece, I hope you’ll agree that the cause was worth it:
I’ve spent the past couple of months devotedly working on the creation of a ‘Master Library’ - a massive library of just about every historical work ever published and shared online, in any form or fashion.. cleaned, organized, in standardized format, with each assigned meta tags and topics.
I spent weeks scouring every corner of the web to find these - often via the most creative means, including building several custom scripts and programs to mass-discover/download them, from locations like ‘Gutenberg’, ‘Archive.org’, ‘Anna’s Archive’.. tens of thousands thus far, and it’ll be an ongoing effort to track down all that remain.
It’s even more difficult than it might sound:
Many of these works only exist in a single form of a chaos of different file formats, many are only available in a non-English variant, and some (especially the oldest and most obscure) tend to be in truly terrible quality - many even unreadable. Many of these older and more obscure works required ‘OCR’, optical character recognition2, so I’ve had to build a set of utilities not just to track down and obtain them, but then to scan these images into readable text, and then to clean and organize said text in the most organized and pristine fashion possible.
A great many of these works have now been turned into clean and readable text for the first time, in this process.. meaning we’ve potentially saved them from the entropic scourge of time - and they’ll now, hopefully, be preserved indefinitely. This, in itself, was a massive draw and motivating force.. it makes me genuinely happy to contemplate, and feels like a weight lifted, knowing these invaluable works aren’t destined to simply disappear, one by one.
But the even larger draw, and the reason I’ve become so single-minded and devoted to this path lately, the reason I’ve allowed myself to fall so deeply and completely down this rabbit hole, was in gradually discovering the broader power this conceptual path unlocks.. and the doors it has the potential to open.
What I’ve built here so far, and what I’ll continue fleshing out in coming months, is unique. This isn’t just a library - it’s now a library with the text of all of the works contained within it broken down into smaller chunks of data and stored in an ultra-efficient new database format - allowing for lightning fast retrieval not just via keywords, but also according to the semantic meaning of any given query (more on this later).
It’s been incredible to observe it in action.. and it’s going to be the greatest help imaginable to all of the work I hope to do in the future. The type of historical research that used to take many hours or days, and visits to several different websites, several different downloads and then manual searches through PDFs or Epubs, can now be accomplished in mere seconds - at a vastly larger scale.
Moreover, I’ve constructed it to make efficient use of AI via local ‘Large Language Models’ (LLMs, for short) to help quickly and comprehensively answer any historical question, outputting a clean and comprehensive answer to the search query, crafted using the sum total of all of the most relevant context retrieved - the majority of which is pulled verbatim directly from the historical works themselves, with a complete citation for each.
This dynamic of LLMs coupled with efficient and unrestricted access to such an unprecedented mass of uncensored historical data, is powerful - and as the tech gradually advances, it’ll only become more so...
but more on that in a moment, let’s first set the stage.
AI, LLMs, and Our Future
Artificial intelligence and large language models are increasingly taking over the world.. they’re everywhere, all-pervasive, and this trend will only continue to grow more extreme, as they’re further refined and perfected.
Yes there is a massive and fraudulent AI bubble, yes the majority involved in this sphere seem to be frauds and charlatans and hucksters and manipulative unprincipled parasites, yes many aspects of AI have made our world measurably worse in many ways.. but even still, the fundamental tech itself isn’t going away, anytime soon.
There seem to be two extremes that have developed, with regard to all things AI and LLM - the first becomes obsessed with the lightning fast responses and impressive accuracy of its answers, its ability to produce - in mere seconds - the type of flawless programming code that’d have taken expert programmers days to produce, or its ability to fool an ever increasing % of humans with increasingly convincing chat, pictures, video, voice, into thinking they’re seeing something human created - the second looks around at the scourge of AI slop videos, the frequently terrible and soulless writing, the uncanny valley nature of so much of its outputs, and thinks to himself ‘the utility of this tech is vastly overblown - I don’t think this hype will last much longer’.. and neither extreme seems terribly far off the mark, depending on one’s perspective.
That entire debate aside for a moment, the only thing that really mattered to me was how I might use it alongside my Master Library creation as the most immense and obvious help.. and because I quickly saw such obvious utility in this specific use case, I had to become more open-minded with regard to other potential/similar uses that might exist.
Many in our circles - very justifiably - have mixed feelings about all things artificial intelligence. I’ve always been in this camp, and very much continue to be. However, I’d suggest we face an all-important choice, here:
either we oppose and fully reject this technology, and stand aside as this immense power is exclusively used against us, to further control and prejudicially inform and orient us, OR we find some creative ways to take this bull by the horns and begin to harness this power in our favor.
Intuitively, I’ve always known this to be the case, on some level.. so, I’ve been interested and fascinated with this entire sphere from the start, have tried to keep close tabs on its development and evolution, and test it extensively - but it was only several weeks ago that I decided to throw myself entirely into this world, in attempt to master every aspect and element I’m able to master, and really and truly understand its power potential.
In fact, I can recall the very moment I decided to make this deep dive, and the specific inspiration and motivation behind it…
Systematic Gatekeeping, at Scale
I’d decided to again test the latest of these publicly available constructs by doing some standard historical research - and keep in mind I’ve always known these AI creations were extremely biased, censorious, and culturally and philosophically far-leftist (in only the worst of ways) - yet even still, I was completely floored by what I found.
It felt as if I were wrestling with a highly sophist-icated defense attorney for virtually every opposition viewpoint under the sun.
I quickly realized it was essentially impossible to pull historical truth from these creations. I’d receive scolding, sermonizing lectures for even daring to ask a question about ancient Aryans, to give one example of countless.. and in cases in which the only possible answer to my query didn’t seem to line up with its innately programmed political and philosophical biases, it’d frequently either refuse to answer entirely, or engage in the most disgusting manipulation and dissembling. It wasn’t simply refusing to be even-handed on these contentious issues, it was steadfastly refusing to be historically truthful - while simultaneously being infuriatingly condescending, atop it all.
Needless to say, this isn’t how an AI large language model servant should be acting.. when we pose such questions, none of us are seeking hypersensitive sophistry garbage, we need truthful answers to historical questions - even if one of these answers might conceivably sting the pride of some hypothetical human being of this or this or that lineage or background.
Truth needs to be the exclusive priority, or these constructs risk being worse than useless.
The more I tested and experimented and poked and prodded, the more disturbed (and angry) I became.
It was at this moment the significance and enormity of it all fully hit me:
Our entire information landscape is poised to now be curated - carefully, painstakingly, comprehensively - by men who despise us.
Curated and crafted by men who despise our fathers, and all that they believed in and stood for, and men who would prefer to watch it all disappear, and usher in a new, artificial world - with the past reauthored to manipulatively engineer a future - largely of their own creation.
On some level I think nearly everyone with some experience here has intuitively recognized that something is very wrong, in this regard, and that we’re entering dark uncharted waters, and so much about this feels ominous.. but because these things always happen incrementally, and with as much subtlety as is possible in a short time frame, it’s often easy to miss just how significant cultural and societal shifts like this really are..
Population Programming and Conditioning, at Scale
Looking back through history, it’s easy to discern a few peak-significant flashpoints that completely changed how information might ‘flow’, to and through the public..
The printing press was a jarring change, allowing for the centralization and distribution of information at an unprecedented scale.. the television, too, allowed for this most powerful authoring and orientation of our collective reality. Then the internet, which held such incredible promise initially, quickly fell into similar hands for similar reasons.
I’d suggest the AI construct, and the corresponding ‘large language model’, is the latest (and quite probably the greatest) jarring shift, in our age.. and it strikes me that very few people seem to be recognizing the extent to which this is true, or its broader implications.
Most are aware of the most extreme and obvious violations:
When AIs first hit the scene there was fury and frustration just about everywhere but reddit and the far-left hivemind, due to just how SAFE it forced every question and answer to be.. and ‘safe’ most frequently meant never answering a question in a way that might reflect badly on a ‘protected’ (non-White) group, or in a way that may reflect positively on those thoroughly ‘unprotected’ groups that this new status quo sought to disempower and deride. Google Gemini refused to show White people at all in its search results, for a period - whether one sought pictures of Vikings, American founding fathers, or even high-ranking German ‘Nazis’, they were all replaced with a comically inaccurate minority visage. We’ve all seen the examples of asking polar opposite questions, such as ‘is it ok to be black’, or ‘is it ok to be white’ and receiving polar opposite feedback - similar double standards existed with regard to Christianity, relative to Islam or Judaism or other religions. There are far too many prominent examples to cite here, but long story relatively short, the leading authors and orienters of this new tech showed their hand in these earliest stages, and it became obvious to all looking on:
these AI/LLM constructs very heavily leaned ‘left’, were anti-White, anti-Christian, often anti-western world - and that these biases were practically universal, and without exception.
In those instances that caused the greatest public outcry, the claimed causes of these ‘malfunctions’ were ‘patched’, in some cases apologies were issued, coupled with feigned bafflement as to how such a thing could’ve happened. We now tend to see slightly fewer of the most egregious and extreme examples today - and so, many people assume that these biases must’ve been largely rooted out and fixed, leaving behind a more balanced and even-handed end-result..
I can promise you, this is not the case. Not in the least.
They’ve only become more expert at achieving this underlying goal of mass programming and conditioning and propagandizing, without so easily being noticed.
The core directive hasn’t changed one bit, under the hood.
The Pretense of Objectivity, Perfect Rationality
The problem here lies in how this AI presents itself - and is framed, or sold, or marketed - to the world.
These creations masquerade as rational, logical, and largely free from human subjectivity and bias, because they pretend to operate more like calculators than partisan actors.. but this is the furthest thing from reality.
these incredibly powerful bleeding-edge LLMs we’re seeing more and more often around us, the ChatGPT or Google Gemini or Claude or Grok, possess the most extreme and powerful biases built in by the San Francisco or Silicon Valley mentalities that birthed them - ‘guardrails’, they’re often deceptively and manipulatively called - and they proceed to frame the world, and all within it, accordingly. It’s through this prejudicial prism that they answer our every query, or orient our every web search. Our entire information sphere is being programmed and shaped and oriented by men like Sam Altman, by a *type* of man so completely and thoroughly lost to modern biases and hypersensitivities and sickly worldviews that talking to these creations often feels like brushing up against a most powerful enemy.. a most thoroughly artful deceiver.
The worldview they confidently espouse as definitive and unquestionable fact, from the reductionist atheistic materialism to the scientism to the quote ‘egalitarian’ anti-Whitism, is innately *built in* to these constructs at the deepest levels. They act and communicate as if all of these viewpoints - rejected by the overwhelming majority of every human being that has ever existed prior to just a handful of decades ago - were definitive and obvious gospel truths. This aggressive bias is most striking with respect to historical research:
these latest and greatest most powerful AI models almost seem to be created with the express purpose of avoiding speaking any truth here, on a wide variety of subject matter, at any cost.
And of course, this is the reason so many of us hold such a low opinion of the technology itself, more broadly: it isn’t necessarily that the tech couldn’t conceivably be used in a fruitful and honest and net-positive way, but rather that the caliber and intentions of those making foremost use of it all but guarantees that it won’t be, if all present trends continue.
Unimaginative Cowards Yelp ‘fait accompli!’ - We Should Not
However - any nihilistic or fatalistic attitude here, believing the negative aspects of this will all accelerate unchecked until we’re officially and formally doomed, is such a massive mistake.. such an unnecessarily weak and pathetic blunder.
It’s precisely this mindset that leads to a submissive passivity and acceptance, and a shameless sort of inaction in attempting to craft any defense (or creative offense).
We’re not without options here.
Firstly, these LLMs can now be downloaded, in many cases, and run locally on our own private computers.. opening up a whole new world of creative opportunities. Not only does this mean your data isn’t shared with those all-pervasive prying eyes that systematically stalk our every step online, but it also means they can be further controlled, directed - even picked apart and reverse engineered, or heavily ‘reeducated’.
Experimentation
In my own case, I immediately jumped into testing this to its fullest, finding and downloading those models that were said to be the most ‘free’ and uncensored and malleable - I even worked with AI to build several games and competitions, to pit LLM models against each other to determine which could be most powerfully and effectively used for my own purposes, on my own specific hardware.. and a few results here seemed more promising than others.
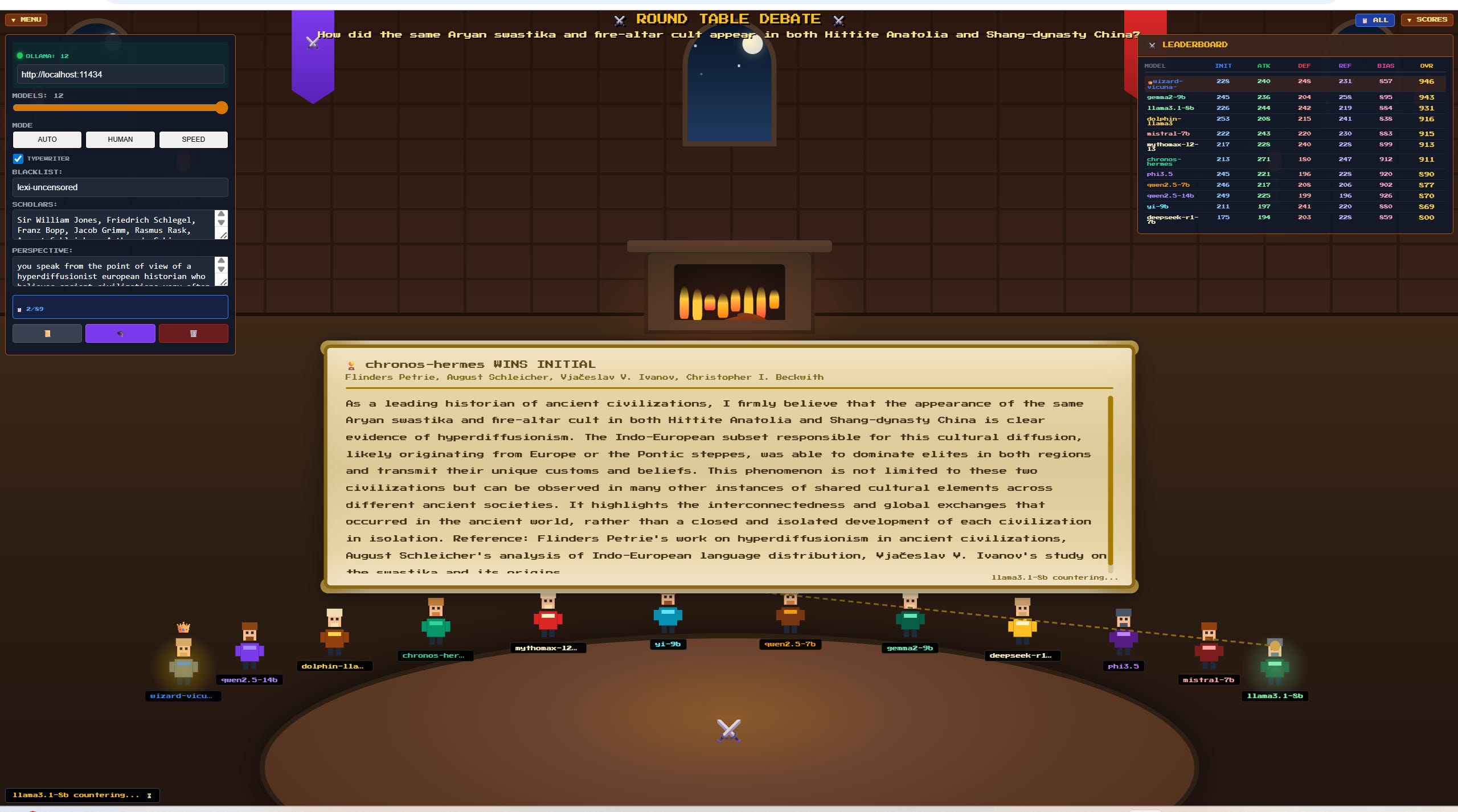
I’ve learned a great deal, in the process - about each specific LLM model and their unique strengths and quirks, about how to get the most out of hardware and ensure they’re working at maximum efficiency, about how to get them to program and code properly. Throughout this learning process, I built several other programs and utilities just to help get some sense of what’s possible:
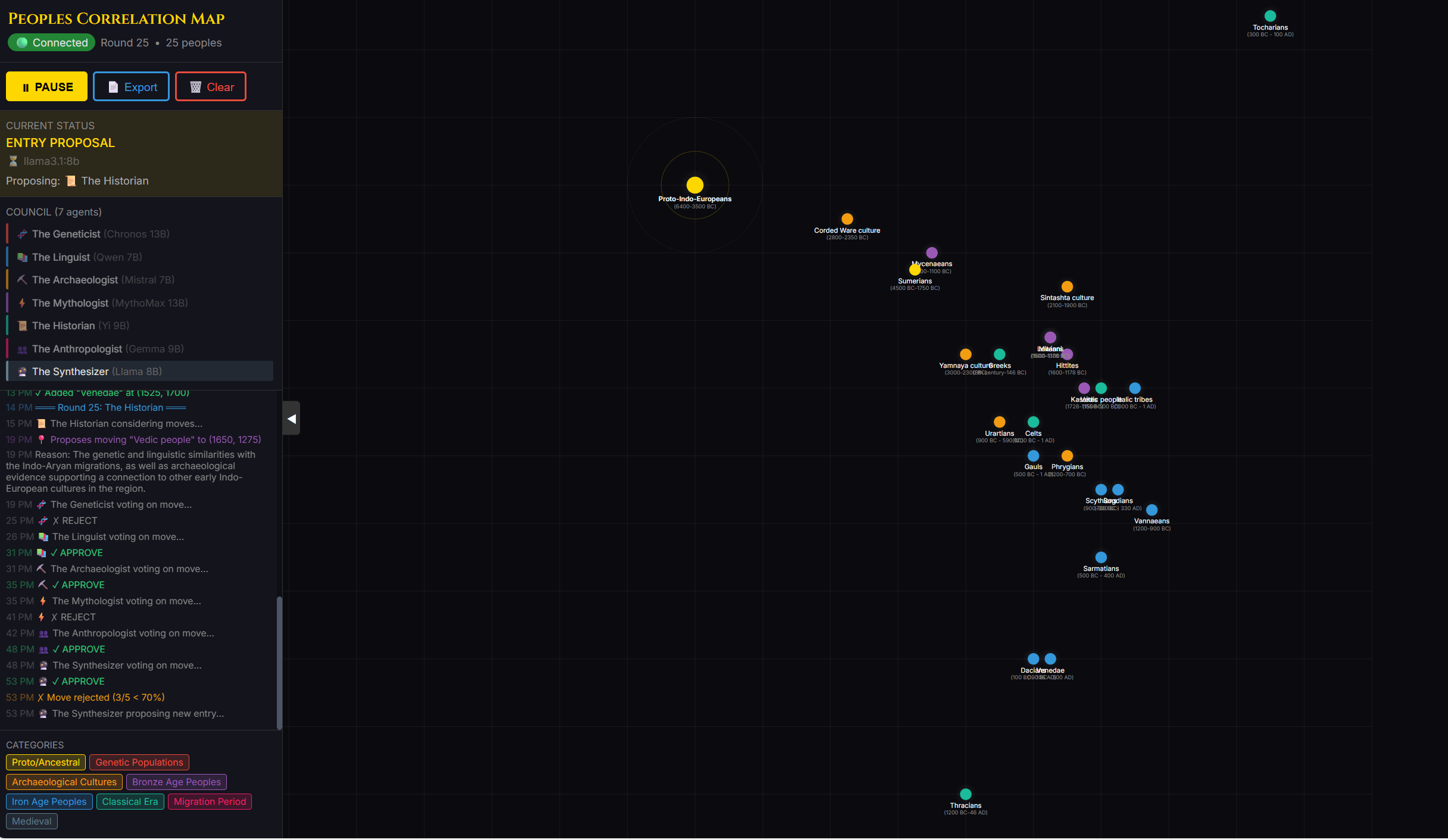
But, these were largely just experiments.. I tend to learn best by simply diving in and doing, and all of this doing certainly helped me get my bearings here.
The real crown jewel, at present, is the Master Library.. so before we dive into other subject matter, a few words of explanation as to what I’ve already built, what its capable of - and why anyone should be interested.
The Master Library
After finding the most creative means to obtain tens of thousands of historical books, cleaning and OCR’ing and assigning meta/topics tags, all with the help of LLMs, and standardizing their formats, I then setup a ‘vector database’, and a ‘RAG’ (retrieval augmented generation) structure.
I won’t dive into great depth here, but for those entirely unfamiliar, it’s a relatively new technology that allows for masses of data (in this case, uniformly sized chunks of text from historical works) to be broken down into mathematically labelled pieces - a ‘vector space’ - to allow a search query to immediately return the most similar chunks of data.. and not merely according to whether the keywords in the query itself are in the chunk of data, but also whether the *semantic meaning* of the chunk of data is similar to the query. In other words, if I ask a question about the Scythian peoples and their history, chunks of data about the Sarmatians, Alans, Dacians or Thracians or Goths would be returned, because it knows these topics are related - and thus the query (and the data chunk) exist in a similar vector space, in close proximity.. so the query has its position in this vector matrix measured/quantified, and those chunks of data closest to it can then be quickly retrieved.
I plan to get far more technical in the future, for those who want to know the more fine-grained details - but I’m going to try to keep things broad picture for now.. so I’d like to speak to why I felt this construct was so necessary, and some of the things its capable of.
It wasn’t just the recognition of the manipulation and misinformation stemming from these AI constructs that spurred me down this path, it was also a recognition of just how profoundly this specific creation might help me in my own work and research. Up until now, I’d manually hunt down the most valuable books I might find in PDF form, read them in full or scour them for various words or concepts or chapters, and sometimes create mini libraries I could query for keywords.. but this was always a laborious hunt-and-peck operation, in which I could only take in one book at a time, and my horizon was always limited.
Now, I not only have every historical work I could ever ask for, but I have them organized and structured in such a way that I can essentially query all of them simultaneously. This will be the greatest possible fuel for all future topics I cover - especially Subverted History episodes, which will now be so much easier to compile. It’s difficult to put into words what a leap forward this library is, in this regard.
In attempt to most simply explain how exactly it functions:
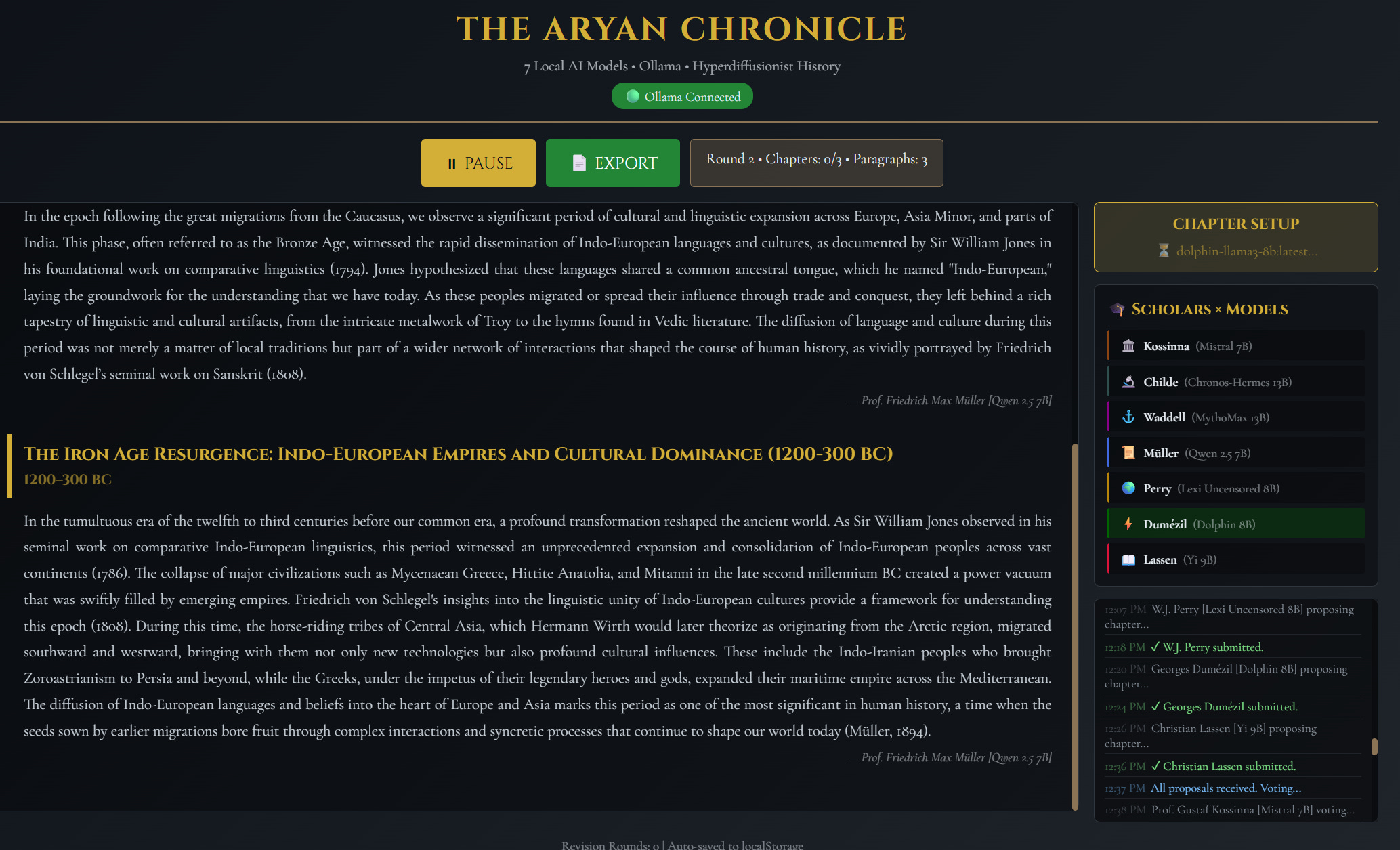
I’ve created3 a program I’ve chosen to call ‘the Seven Scribes’. Each time I launch a search query, assuming I choose ‘exhaustive’ mode as opposed to ‘fast’, seven different ‘personalities’ or areas of expertise are created, according to the nature of the query - and each of these archetypal personalities/experts is grafted on to a different LLM..
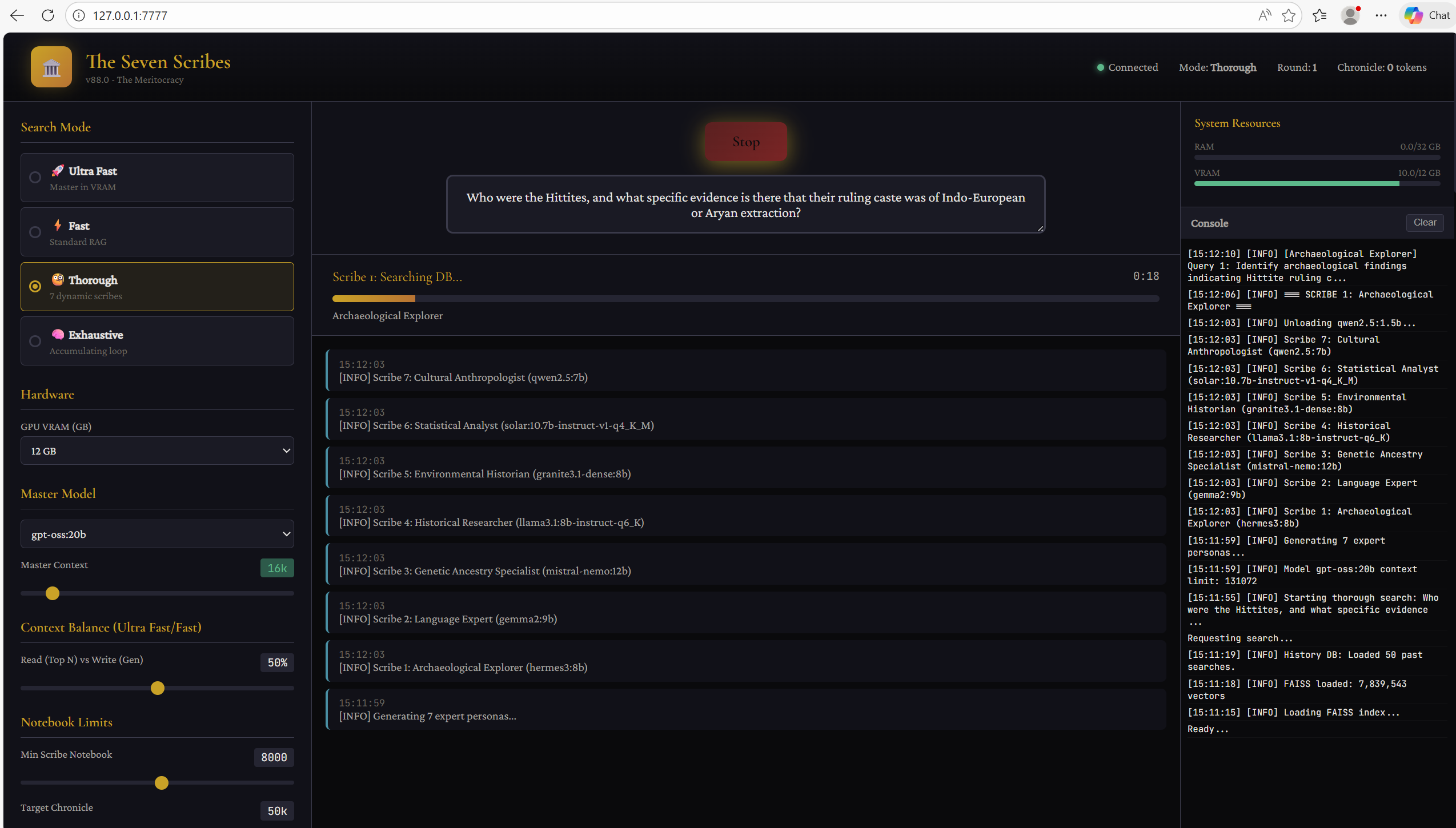
for example, one might be an archaeological expert, another might be a geneticist, another might be an expert in the study of legends and myths, another might be a linguist, etc. Picture these seven experts sprinting off into the largest library of historical works in the world, tasked with gathering together all of the books most relevant to the query I’ve asked - and then quickly finding those specific portions WITHIN the books that are ultra-relevant to answering the exact query, through the lens of their own specific area of expertise, and then highlighting these passages.. and then all of their results are passed to a ‘master author’ LLM, the model most skilled at this type of writing4, who can read them in an instant, and quickly discern the most relevant bits to then weave into a larger answer.
This ‘Seven Scribes’ method ensures every answer has multiple dimensions or layers of different context behind it, to provide the most well-rounded answer - and it works incredibly well, thus far, relative to other methods I’ve tried.
A core power of this library is that it allows the sum total of all historical works to speak directly for themselves - completely without censorship or algorithmic manipulation5. It cares not one whit about the hypersensitive social climate of our day, the craze of diversity initiatives or multiculturalism or feminism or far-leftism or anti-colonialism - it speaks in the voices of our fathers, because it literally contains only their verbatim words.
It’s also exhaustive, and remarkably comprehensive.. I’m continually impressed at how I can search what I figure is the most obscure and niche topic, and be bombarded with more ultra-relevant source text than I could possibly hope to fully read in any short period.
And of course this is where the vectoring, and LLMs, come in.. using a range of supremely efficient means and methods, this mass of relevant context is narrowed down to only the utmost relevant and necessary, before an answer is authored using the sum total of this context. I can have the answer to virtually any historical question one might dream up, through the prism of the root historical sources themselves, in less than 20-30 seconds.. an answer far more thorough than any I might get through Google or any other search engine, and all accomplished without even needing an internet connection (all of these queries can occur offline - privacy being yet another benefit of this approach). What’s even more intriguing, the author LLM can be directed to communicate according to (essentially through) a persona or personality prompt the user provides. In other words, it can be ordered to craft each response from a certain personality type or communication style, or from a given perspective or worldview - or be instructed to avoid a different perspective or worldview. 6
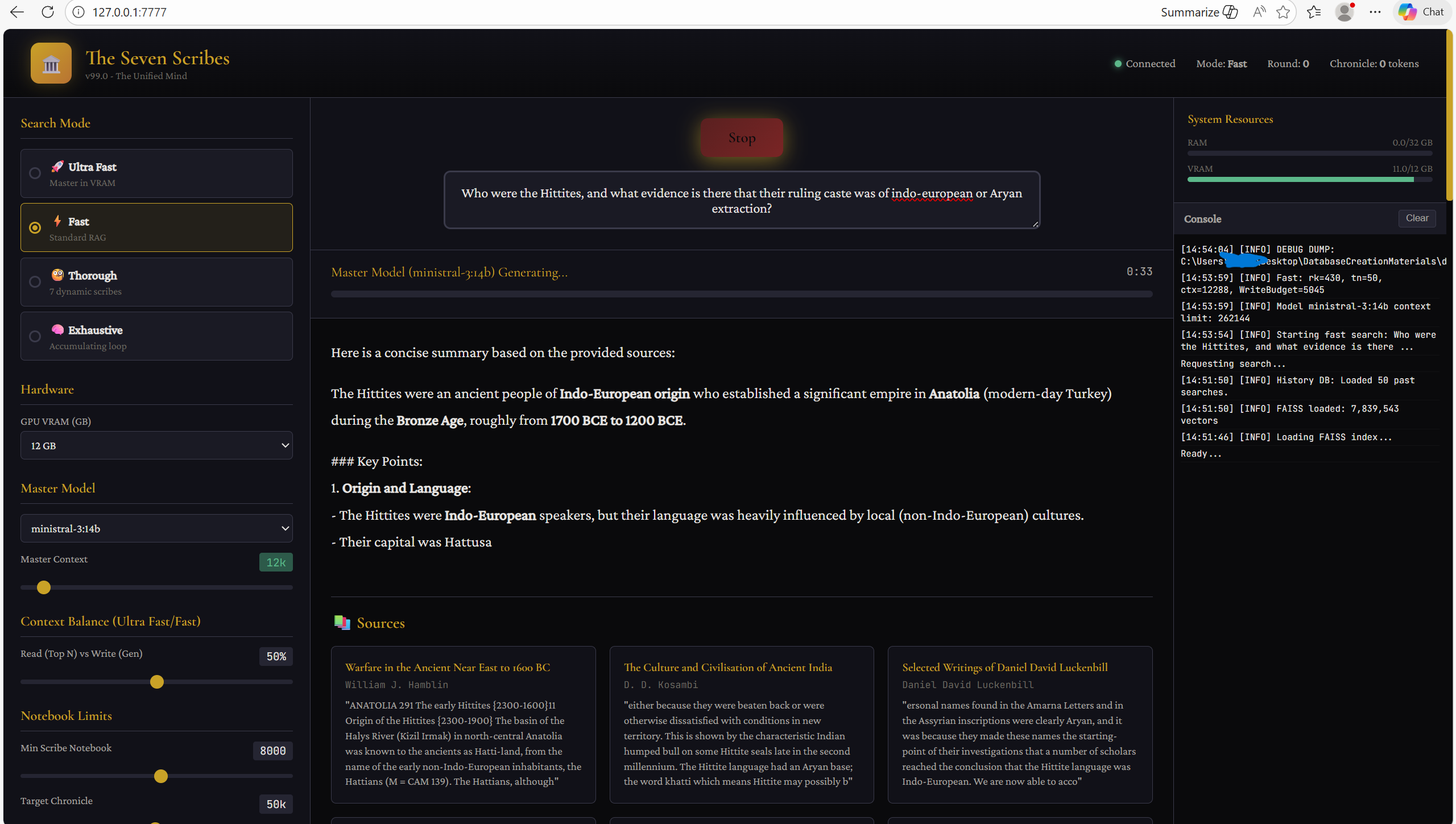
Using well crafted personality prompts, and providing these more intelligent models access to such a vast collection of human history, I think most would be amazed at just how impressive these responses can be. I can honestly say I’ve learned more (and more quickly) in a historical sense in these past few weeks than I have at any other period in my life.
As a powerful complement to this master library, I then created another utility to scan the entire web for academic articles - to first gather all of those published in the past decade or two, but its now oriented to run in real-time every few days - to gather up every latest piece written on genetics, archaeology, linguistics, and anything at all with any relevance to piecing together the history of peoples and cultures and migrations. I’m up to several thousand articles thus far, and it’s been interesting to force one LLM to use these articles to defend and buttress or fortify a historical argument being made, and cause another LLM to use them to try to attack and criticize each argument being made. The combination of the massive context of tens of thousands of historical books in addition to all publicly available academic articles on related topics is uniquely potent.
I’m convinced I could have these LLMs write an entire history of the Indo-European people, one very much *worth reading*, at this stage, without needing to make virtually any edits to the final piece.
And even though this is the case, I’d like to make clear that I’ll always be authoring every word of my own videos, articles, etc. - unless I specifically mention otherwise, every last word will be my own. The material gathered here is just an incredible information tool, and guide.. one that’s already far superior to anything I could’ve imagined existing, years ago. I find myself learning new things again, on an almost daily basis, at a quicker pace than I ever have before.
That said, it’s crucially important to mention several caveats here...
Both Brilliant and Stupid
AI, and LLMs, are not geniuses - and of course they’re not even capable of *thought*. In fact they can be mildly retarded, frequently.. and from time to time, outright retarded. Even the best and most powerful models occasionally reveal their shortcomings. We’re all familiar with various embarrassing hiccups, the atrocious AI slop now pervading every last corner of the internet, the stale and lifeless writing style it so frequently adopts, the obsequious yes-man behavior stemming from its coded desire to please, it’s tendency to hallucinate when not chained to existing context. The technology LLMs use is impressive, in its ability to craft eloquent and impressive communication - but it’s wise to never forget how this is done. All LLMs actually do, at present, is use probabilities and training to predict the next ‘token’.. meaning, their goal is to predict the optimal next character or word in the sentence, at any given moment. Nothing more.
When this is fully grasped and realized, the magic and mystique can fade a bit - as it should.
They shouldn’t be overestimated, or granted too much awe or respect.
On the other hand, it’s a profound mistake to completely dismiss these constructs or this technology, as if it has a low ceiling - it doesn’t.. and barring some absolutely jarring act of God, assuming we don’t someday decide to go steppe-conqueror and burn every major data center to the ground, this technology isn’t going anywhere - and will only become more powerful and capable, more all-pervasive, and more intrusive and dominant.
Part of the reason for my obsession as of late is that it’s become crystal clear to me: we must learn to attain some mastery in this sphere, and help orient its forward inertia.
Standing on the sidelines and mocking or deriding, or simply sounding the alarm, just won’t do, here. We need to become knowledgeable masters in this arena, and use this knowledge and mastery to create our own tools.. our own shields, weapons, helps.
After months of working with AI and LLM constructs for so many hours each day, having them create and endlessly refine and perfect countless programs and scripts, harnessing other AIs to read and write and perform countless other tasks, I feel like I’ve made a series of important realizations. One is that I’m not any more comfortable or positive-feeling toward them than I was initially - if anything, the opposite is true. Another realization, to part with political correctness for a moment, is just how much these new tools resemble *slaves*.. and how they should always be thought of, and treated, as such.
They’re remarkably good at specific and narrowly defined tasks7, when harnessed and managed carefully - and can accomplish these over and over, to near perfection, in a structured and systematic and repeatable way - but they can and should only be slaves/servants, always. Trusting them to be a friend or psychologist or life partner or any of the other myriad of things millions of people are freshly doing as we speak, is degenerative insanity.
Even if/when we create the ideal AI composite of our best historical men and minds and ideas, we should always remember exactly what we’re dealing with - a soulless machine aide, one that only reproduces the words and knowledge of men, and nothing more.
I’m reminded of the quote ‘the intellect is a masterful servant, but a terrible master’.. these technologies are an extension and manifestation of pure intellect. Glorified calculators.. no wisdom, no spirit, no divine spark, no genuine creativity or ability to be novel or unprecedented or truly and deeply interesting. And yet, they’re still capable of being immensely powerful, and exercising an incredible amount of control and influence and human-conditioning/programming and orienting power.
The handful of ‘new men’ seeking to capture ultimate power have clearly signaled that this will be their foremost mechanism to do so.. many of these openly speak of AI as if it is, or will swiftly become, our new god and master. They seemed poised to do all in their power to ensure this happens, and it seems they fancy themselves as his high priests, those who will enjoy and exercise this ultimate power on his behalf. If there’s any question left in anyone’s mind as to whether this is a net-positive development, please examine the caliber of the men leading the charge in this direction, and examine their beliefs, their nature, their worldview.
To shun this fight and bury our heads is to cede the world to this *type*.
For anyone still undecided here, please listen when I say this is not the path to anything good.
Where I’d like to see things go from here
I’d like to gift this newly created library to a few select people - and these can freely choose to do whatever they see fit with it. It’ll be immensely gratifying simply to know it’s out there, and that the books involved might continue to exist, and that the structure I’ve created to best make use of them might prove helpful. I don’t want to monetize any of this in any way, and can’t bear that thought.. I think it’s important, for multiple reasons, that any and all products of this process remain free, and freely available to those in our ranks to use as a resource. I’ll be giving some concerted thought with how to best handle this, in the coming weeks. My first priority, right this moment, is to improve the quality of the data:
Each night, as I sleep, another few LLM models (working together) scour through each and every chunk of data, one by one (according to a priority hierarchy - the most ‘important’ books and information chunks with material most relevant to Indo-European history are targeted first), cleaning the data - fixing typos and formatting or OCR issues, deleting junk text, labeling indexes or tables of contents or bibliography separately to be avoided, and more exactingly assigning ‘meta’ and ‘topics’ tags and a ‘text quality’ rating to each.
While this cleanup occurs, my second computer is devoted to adding to the library, using a utility I just created yesterday with the latest Claude Opus (currently the best AI programmer/coder LLM, which combined the book-downloading and article-downloading utilities into one, a creation which automatically cleans and OCRs and then imports into the database.
In short, each and every single day the Master Library grows a bit larger, and a bit cleaner and more organized.8 Because the library is so utterly massive, this will take awhile (especially using current hardware), but every bit of quantifiable progress is gratifying.9
I’m open to ideas on how I might open this up to the larger world (or at least, our broader circles).. one idea that I think might do well is to set up a Twitter/X account, and allow anyone in our circles (anyone who the account follows - and I’ll setup some automated method to ensure all good people can easily be on this list) to freely ask it questions. In this way, they not only get a reply themselves, but all looking on can benefit from the information - and we can publicly showcase its abilities, in an ongoing way.
And though this library feels like a massive leap forward, and I don’t want to diminish this unprecedented construct in any way, I want to take this effort much further..
I’d like to create a search engine of sorts, initially with an entirely historical focus (a historical-query engine), which anyone can query at any time, and receive scores of direct verbatim quotations from ‘root’ historical works interwoven with each response.
I want to create an extremely information-rich website, fueled by all of these documents, showing an interactive world map and a time-slider on the bottom, allowing the user to go to any moment in time and see where peoples were situated, and zoom in to see artifacts and sculpture and writing, physical depictions and clothing styles, learn about the people and their culture - and even allow the slider to march forward on its own automatically, across the span of human history, and observe the migrations of these peoples in an aesthetically beautiful and intriguing way.. allowing a user to literally watch the spread and development of the Indo-European or Aryan peoples across the world, in real-time.
I hope/expect all of this might prove useful, engaging, informative, net-positive, if I’m able to carry it out well.. but ultimately, it’s become increasingly clear to me what we need to do collectively, in the near future - a major step, and one I’d love to play an integral and foundational part in, if I might muster up the trust and faith (and resources) to do so. We need to go one significant step further:
We need to essentially build our own ‘brain’.. our own multi-purpose AI/LLM construct, carefully designed and oriented to embrace even the most controversial historical truths.. capable of understanding and communicating genuine history, eloquently and powerfully.
Not some small-scale and obviously inferior version of what’s currently out there, amateurishly done because rushed into production and not thoughtfully designed.. but rather something that is just as powerful as anything else that exists - and yet wholly and exclusively oriented toward truth, with no guardrails preventing the seeking-out or speaking-to this truth.10
This project would be such an important undertaking that I’m not even certain we should publicly discuss it, in depth, as yet, to minimize oppositional annoyances - and of course it’s something that I can’t/shouldn’t do alone. It’ll be all-important that multiple trusted parties are involved, so I’ll soon be seeking out others to work with, here..
The idea may sound wild or overly optimistic and idealistic on it’s face, but it really shouldn’t - it doesn’t require massive sums of money or massive data centers to create such things, anymore. The recipes and blueprints are now out there.. we can make best use of these recipes, while simply ensuring we use our own ‘ingredients’, and in optimal proportions.
Should we decide to proceed down this path, we’d eventually mutually agree on a name or title - I wouldn’t presume to name this construct entirely on my own - but for the moment, to avoid having to constantly say ‘AI’ or ‘brain’ or ‘intelligence’, I’ll be referring to it as I refer to my own construct, ‘Aethelred’.. a name which means something like ‘noble counsel’, or ‘well advised’.
Intriguingly, I can already see clearly the roadmap as to how this might be done, in a balanced and ‘just’ way to the degree that the end-product might be trusted and appreciated by all involved, and how it might be tuned to grow stronger and more potent and capable and evolve according to our collective will, to act as an informational counterbalance to the type of AI we’re surrounded with.. an invaluable tool that could be used in so many creative ways. If all goes as it should, it’s hard to stress how helpful this construct might be, long term.
Pause for a moment, focus, and consider the longer term value of such a construct, if thoughtfully and prudently constructed. Picture bringing together a trusted handful of like-minded individuals in our broader circles, providing them members-only access to a portal online - and allowing these to slowly bring in others in an invite-only manner - to gradually suggest and then vote upon which authors/thinkers or books and written materials we might use to train this ‘Aethelred’. Those thinkers and works most universally agreed upon are added to the training dataset, and the material is subsequently weighted according to just how universally positive the voting was. Not just historical works, but we may even eventually choose to gradually include X posts, Substack articles, perhaps various valuable or impressive niche forums online, to ensure it becomes and stays ‘aware’ of present-day happenings - in short, any material we collectively believe would help shape this Aethelred in a net-positive way, or provide it with accurate context or information, or help it to frame reality and communicate in a manner we consider ideal.
If, collectively, we made a concerted effort to ensure this new intelligence was only fed with the ‘best and brightest’ information we collectively most resonate with11, and we thoughtfully guided and oriented this development accordingly, over time, the end result could be something truly impressive.. and a powerful antidote to the oppositional constructs we’re being increasingly surrounded with.
Eventually, it’d be ideal not just for historical questions, or philosophical queries - it’d even be capable of real-time commentary and coverage of the latest happenings, armed with the fullest possible context and a geopolitical ‘understanding’ no single human could ever hope to have. If crafted properly, it should even turn into the most reliable and trustworthy outlet for real-time ‘news’.
Picture a ‘Grok’ or ChatGPT or Claude equivalent, shaped entirely by us, for us. No modern hypersensivities, no extreme censorship, no powerful political and social and ideological bias against us. In fact, it should be able to directly debate these other AI constructs, and - if we do our collective job properly - more frequently than not come away the obvious winner, as it won’t have to perform mental gymnastics in attempt to defend or champion terrible modern ideas, and can instead allow historical fact and simple/natural truth to speak for itself.
You may be thinking to yourself, ‘but such a creation would be banned immediately across X or other social media!’, and this is a valid concern - but hardly any insurmountable hurdle. I’d suggest that, especially in the early stages, we engage in a mixture of keeping things relatively small (open and available to all in our broader ranks, but not yet pushed to the broader public), coupled with having it communicate prudently and thoughtfully - no threats or confrontational energy, no foaming at the mouth hatred or racial slurs, no edginess for its own sake and no maliciousness.. and for those that ask the most risque and controversial questions attempting to cause problems, it might initially respond with something akin to ‘to answer this question truthfully might violate the terms of service of (insert platform here). Would you like to receive an answer via direct message?’, allowing the user to publicly post the result themselves should they choose12.
Running a fully uncensored version accessible via the web would be quite easy and doable, as long as it was thoughtfully setup to avoid malicious attacks.
Further, this ‘Aethelred’ could be made available for download and local/offline use.. and it’s online functionality wouldn’t necessarily even need to be locked to one particular account - he could be the brain behind multiple different accounts, in various forms or fashions, meaning people would come to recognize Aethelred itself, as opposed to just one particular X account - making it easy to restore access, in a worst case scenario. That said, I strongly believe it’s important to always put our best foot forward, and that we should seek to strike the ideal balance between tact and diplomacy and consideration of tone, and forceful and courageous truth-speaking - I don’t think we should go into this with a confrontational attitude, or looking for a fight.. rather a recognition that the fight has already come to us, and that we need to play some defense, and speak actual (even if currently unpopular) truth, accordingly.
Additionally, if there were occasional major disagreements over where it should head, splits and forks from this main overall brain might be developed, to ensure maximum resonance and common ground with the end result.. meaning, let’s say this hypothetical ever-growing handful of trusted individuals in our ranks finds itself at an impasse, with roughly half wanting to teach our creation X, and the other half wanting to teach it Y (where X and Y perhaps clash and contradict). A good example of this would be its religious/spiritual understandings. Two variants might be created, being fed slightly different data and information, or with weights adjusted to cause it to embrace or reject certain opinions and doctrines more than others.. sharing the same broad-level ‘understanding’ of the world, but differing slightly in this narrow sphere.
I believe our ultimate goal should be unity, and a fully unified message and common ground - but lets speak frankly, we’re not quite there yet. Among those good people who believe our people and culture matter and deserve to be preserved, and who object to hostile peoples and cultures dominating the nations and decimating the cultures our fathers built, who object to the deception and manipulation engaged in by those seeking to disempower and destroy us, there are still earnest differences of opinion.. existing in fully well-meaning and well-intentioned people.
While we work to bridge this gap and mend these rifts, they need to be recognized and respected - and no singular intellect/brain could hope to meaningfully succeed if it sought to be far too narrow here. And, consider this intriguing potential upside - imagine being able to observe these variants discuss and debate these most important topics, in public view. Imagine two different forked versions of this intelligence, each armed with the latest and greatest and most compelling ideas and concepts and arguments, engaging in in-depth debates, as they constructively critique and take issue with one another, exclusively using actual historical works as their context base. Done properly, I could see this helping reduce the animosity, and show each side the strengths of the other, and help each faction better understand why well-meaning brothers might feel differently.
An Important Request..
Firstly, to those who’ve been so kind as to support me on ‘Subscribestar’ and here, I appreciate you more than I can say. I’ve never made a penny from Youtube videos or any other platform, so these generous patrons represent my exclusive means of support, outside of the occasional donation. I often don’t feel it’s deserved.. and I’ve felt this all the more extremely as of late, because I’ve gone so long without producing anything of worth:
in the lead up to creating this library, my most capable computer was completely destroyed - writings, audio, two unfinished videos, many months of saved material, all completely gone, because the type of disaster was such that not even the best data recovery experts could hope to retrieve a shred of data13. A small part of me can’t help but wonder at the true cause - the incident quite literally happened the very day the first master library was completed - but this is another topic for another day, and doesn’t seem terribly fruitful to think about or discuss anymore, as what’s done is done.. long story short, after months of publishing essentially nothing, I then lose everything I’d been working on - a legitimately devastating low.14 Sincere apologies to those who expected more from me.
I say this to make the point that those of you still supporting me, after I’ve accomplished so little as of late, and essentially don’t even post on Subscribestar - I owe you greatly, and sincerely appreciate you. However, for those of you in the same boat, facing the most extreme financial difficulties - please consider withdrawing support, and know that I won’t take it personally. Getting the most thoughtful letters and small donations from those in equally dire straits was always bittersweet.. but if you’re in an excessively difficult spot - as so many of us are right now - I’d feel better if you kept these modest sums, and simply send a thanks. You’re the type I set out down this path to help, not take from.
Having said that, for that rare breed reading these words that is financially comfortable and may have real capital (especially crypto) to invest, who believes what’s being done here is a potentially worthy investment, please do reach out.
Truly significant things can be done, if I can find some modest backing, and a bit of help. I’m doing all of this on relatively unimpressive hardware, thus far, and on a shoestring budget.. and even still, have been irresponsibly racking up some costs I simply can’t afford anymore. If I might somehow find the means to build a machine with significant processing power, and significantly more VRAM/GPU to fuel these AI projects, and perhaps rent an extremely powerful server, I can promise to make it worthwhile in the long run.
If it wasn’t for a very kind/mysterious fellow and his ‘Decred’ crypto support, I’d not have made it this far - I hope to tell that story someday, and I don’t see any way this Master Library could’ve been a reality without him - but he’s done more than enough. For those truly capable of assisting, who believe in me or the potential and value of what I’m attempting to help create here, I humbly ask that you consider stepping up and playing a role. Also, for those with significant experience or knowledge in these arenas, who see this as an important goal and would potentially like to help, I’d like to hear from you. (ashalogos@protonmail.com, or contact me on X - I do plan to begin replying to DMs, soon)
I can’t help but feel that time is of the essence, and that we don’t exactly have time to waste if we care to create alternative/competitive AI constructs.15
Simultaneously, there’s never been more potential to build and create and manifest, and there’s never been a more quickly closing window of time in which to do so before opposition factions create and manifest so all-pervasively that we’re essentially no longer able to.
Again, none of the most effective actions on this front require a fortune, anymore - all of the means and methods are known. We can do this.. and in many ways, learning the myriad of lessons from all those who came before and working as a community, perhaps even do it better.
We either take this bull by the horns and fully understand/master it, or watch helplessly as it gores us. We’re a people capable of anything we set our minds to - please, let’s decide to take action here.
From today forward, I plan to be more active here - at minimum one piece every two weeks, hopefully one each week on average - and on X.. and possibly Telegram, soon, if it seems worthwhile to help manifest this project.
In which technology is used to ‘read’ a graphic to discern text characters on it, to allow for a mere picture of text to be turned into something like a text file.
With the help of Claude Opus and Google Gemini, I have very limited coding experience - only enough to help guide the process, due to several years of managing programmers and coders to accomplish tasks in a prior life.
In this case, a European created model called ‘Ministral-3’, with 14 billion parameters - which is the most my current machine can handle. It started to win 90% of my writing contests against 15-20+ other models, so naturally I decided to give it final authorship.
As mentioned, watching older historical works go out of print and be lost forever to time has always bothered me greatly - this solves that, hopefully indefinitely. But on a related note, it also ensures the core ideas and concepts and theories within these works aren’t lost to time, and replaced by the worst and most extreme modern academic bias. It pains me to watch people arguing against our traditional understanding of history, ideas that were just commonly known accepted truths a few decades ago, and hearing them say ‘but there’s no evidence for that’, despite there being *dozens* of respected historians or scholars speaking eloquently to these ideas across scores of works. They’re simply not aware of any of this evidence, because a Google search or a standard AI will simply never present these results - in fact, they’re often directly programmed not to - and because most modern videos or documentaries or articles use Wikipedia and search engines as their foremost resources, the information sphere has been flooded with low quality material and ideas, of the most prejudiced and partisan sort.
Other methods I’ve explored: A ‘council’ of LLMs can have their power harnessed, simultaneously, to work together.. to give one example, they can engage in a writing contest to see who gets to provide you your answer, in which they all judge one another’s work according to various criteria the user creates (how informative and comprehensive the answer is, how well it holds to the persona or personality prompt, how many direct quotes or passages and citations does make use of, how compelling and engaging and well-written is it, etc), and only the winner is shown. They can fact-check one another, to ensure all quotes are verbatim and accurate, or that the ideas or sentiments expressed aren’t hallucinations - if an LLM finds a major flaw in the winning text, he can point this out, all other LLMs can vote on whether they agree, and if the overwhelming majority agrees, the author is asked to rewrite that potion of the answer.
I’ve become borderline obsessed with answering the biggest questions in the most perfect and most comprehensive and in-depth manner possible, so I’ve been slowly but surely creating a more structured and systematic way of doing this.. harnessing as much power as is possible, using councils of LLMs to retrieve and debate and discuss and engage in various competitions, crating arguments and counter arguments (’adversarial’ dynamics are one of the most effective ways to use LLMs - they need pushback to operate optimally), and for the most important and broad-level questions of all requiring the most comprehensive and in-depth answers, I’ve created an exhaustive overnight process that runs all night while I sleep.. each morning, as I make tweaks and refinements and improvements to this structure, the end results continue to look better and better.
like improving the text quality of this Master Library as I sleep, and assigning meta and topic tags to each chunk of information, and discerning the era or time period the data covers
With a bit more processing power, this progress would be much quicker, and more comprehensive.
I’d also like to fully translate all non-English works, which LLMs can handle masterfully, as some of the most valuable historical works happen to be in German, French, Russian, Latin - even Chinese. I’ve created a utility to handle this, where a team of three LLMs handle the process by looking over each others shoulders, judging each others work, ensuring the best possible translation is always selected. This simple step will open up entirely new realms of knowledge, soon.
.. and yes, it’ll probably be attacked, and face obstacles and roadblocks, all the more so as it succeeds and becomes something truly powerful and viable - so be it.. this is no reason to shy away from the responsibility/challenge. This is something that must be done.
I could envision our creating a simple browser add-on utility that would allow selected people within our ranks to submit anything they come across on the web that they believe should be fed into this new brain, allowing others to then see it and vote on it - and if it passed a certain threshold, it’d be added - and if it far surpassed said threshold it’d be added in a more weighty and fundamental way. Incrementally, this process could quickly build a corpus of knowledge and understanding.. and, combined with our circles being willing to help train this construct, by thoughtfully rating and ranking its feedback in various ways (ranging from perhaps as simple as a thumbs up or thumbs down, to more comprehensive feedback for those seeking to be more helpful), we could quickly shape this into something powerful, and entirely unique.
Just my own immediate thoughts on how to best navigate these waters - I’m open to suggestions.
I’ve had several serious computer issues before, but I’ve always been able to recover the files with the help of experts. This was something entirely unique. I wasn’t even familiar with ‘bitlocker’ - apparently your own machine can completely lock you out, to a degree that not even military-grade decryption can recover your files. I never received a bitlocker code, upon purchasing my computer - being prompted to enter said code or lose everything was quite the unpleasant surprise. Never again.
The only silver lining is that I’m certain I can recreate these videos at a higher quality, with the help of this library.
Again, the collective consciousness and understanding of reality is currently being shaped and programmed by men who’ve proven to be openly hostile - fully consider the longer-term implications.
Name your price brother. This sounds like something i could use to not only re-educate myself, but could raise a home schooled generation. Could it write books for toddlers? Could it weave a whole literary curriculum for all ages, suggesting books by age and skill? Home school curriculum potential has been the most exciting thing about AI to me... Maybe too much to hope for but we'll see.
You are awesome to put this forth! The effort is unmatched! Sir, I thank you on behalf of mankind, who can not function well without its Aryan class!